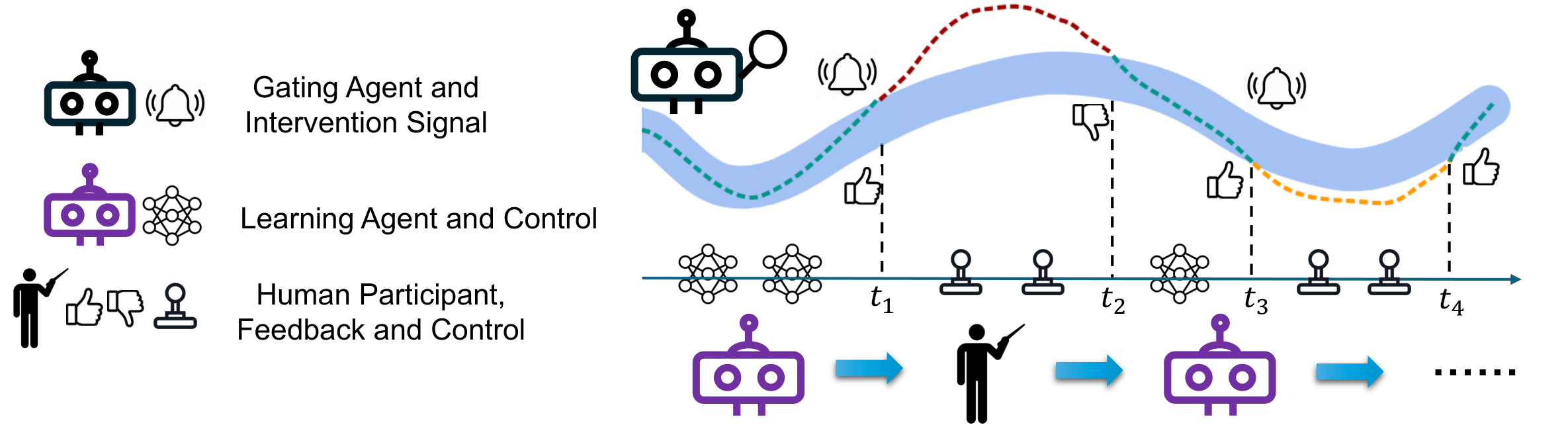
As shown in Fig. 1, The learning agent (in purple) interacts with the environment under the monitoring of the gating agent (in black).
The gating agent decides when to request human intervention.
Learning agent trajectories are in green and human trajectories are in red and yellow.
Human feedbacks are denoted with thumbs up and down.
Feedbacks at \(t_1\) and \(t_3\) are human evaluations on whether the gating agent triggers control switch at proper timesteps.
Feedbacks at \(t_2\) and \(t_4\) are human preferences on whether the current intervention trajectory is better than the previous one.
For example, the trajectory between \(t_3\) and \(t_4\) is better than that between \(t_1\) and \(t_2\), so human may provide positive feedback on \(t_4\).
Method
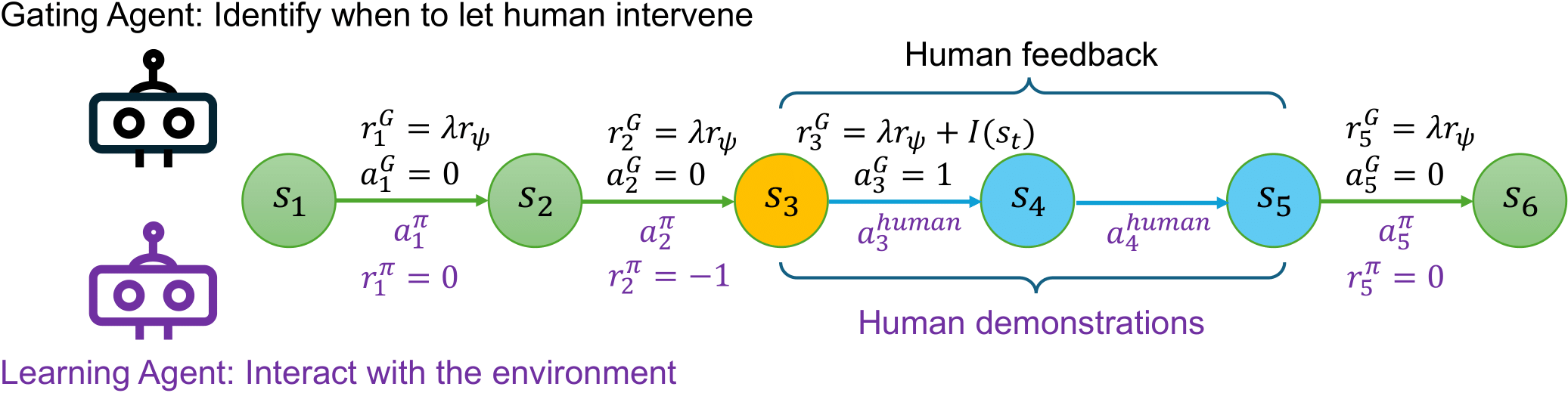
Fig. 2: The framework for training both the gating agent and the learning agent.
To properly train the gating value function \(Q_g\) for optimal intervention timing, human participants follow three steps, as illustrated in Fig. 2:
Providing a binary signal \(I(s_t)\) that assesses whether the current environment state is indeed worth intervention and is intervened in time.
Interacting with the environment for \(T\) steps and offering online demonstration segment
\(\sigma=(s_t,a^{\text{human}}_t,\dots,s_{t+T-1},a^{\text{human}}_{t+T-1})\),
aiming at guiding the learning agent out of the region that is dangerous or no longer needs exploration.
Providing a preference signal \(p_t=P_\psi[\sigma\succ \sigma']\in\{0, 0.5, 1\}\),
indicating whether current segment \(\sigma\) is better than the previous segment \(\sigma'\).
Results
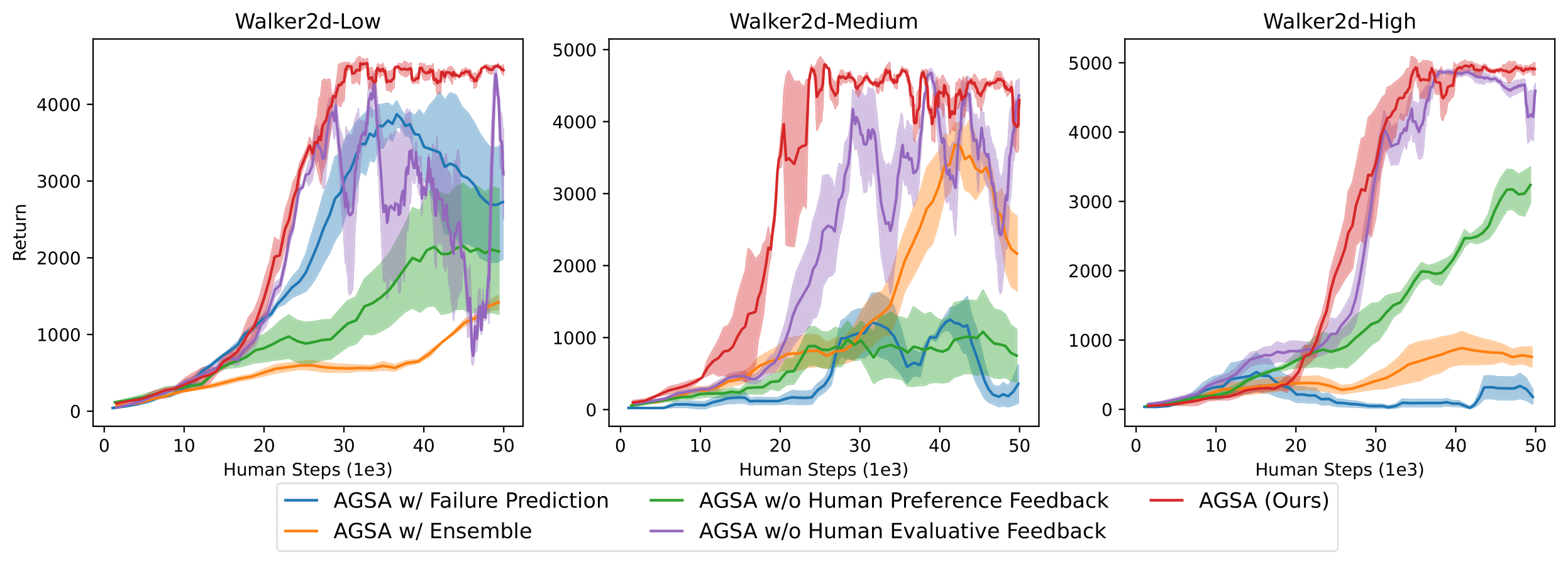
Fig. 3: Algorithm performance curves for the ablation study in the Walker2d environment.
The lines are average return across four different trials and the shadow areas denote the standard deviation.
We present performance curves for ablation studies in the Walker2d environment in Fig. 3. We consider the following methods:
“AGSA w/ Failure Prediction” and “w/ Ensemble”
are alternative approaches for constructing the gating agent. Both methods keep the learning agent
training unchanged.
“AGSA w/o Human Preference Feedback” and “w/o Human Evaluative Feedback”
remove \(r_\psi (s_t, a_t)\) and \(I(s_t)\) respectively when computing the gating agent reward \(r_G
\).
“AGSA w/ \(r_\psi\) as \(r_\pi\) ” refers to using the reward model \(r_\psi\) trained from human preference feedback as the proxy
reward \(r_\pi\) to train the learning agent, in the same way as PbRL algorithms.
In the following video, we visualize two stages of training in the Walker2d environment, both with and without simulated human intervention.
At the early stage of training, the learning agent is likely to fall down without intervention due to its poor ability to balance.
Instead, the gating agent can trigger simulated human intervention to prevent the learning agent from falling down, leading to a good behavior
policy that facilitates the exploration process.
Near the end of training, the learning agent can walk stably without intervention, and the gating agent can learn to avoid unnecessary intervention.
Video 1: Training visualization in the Walker2d environment both with and without simulated human intervention.